One Month Out: A Training Update That's Less "Rocky" and More "Bloke Who Occasionally Runs"
The Fife Pilgrim Way Ultra is in approximately one month. Fifty-six miles from North Queensferry to St Andrews. Fifteen-hour cutoff time.
I thought this should be a fairly straight forward project. I quickly ran into the brick wall that bliss symbols didn't have a keyboard...
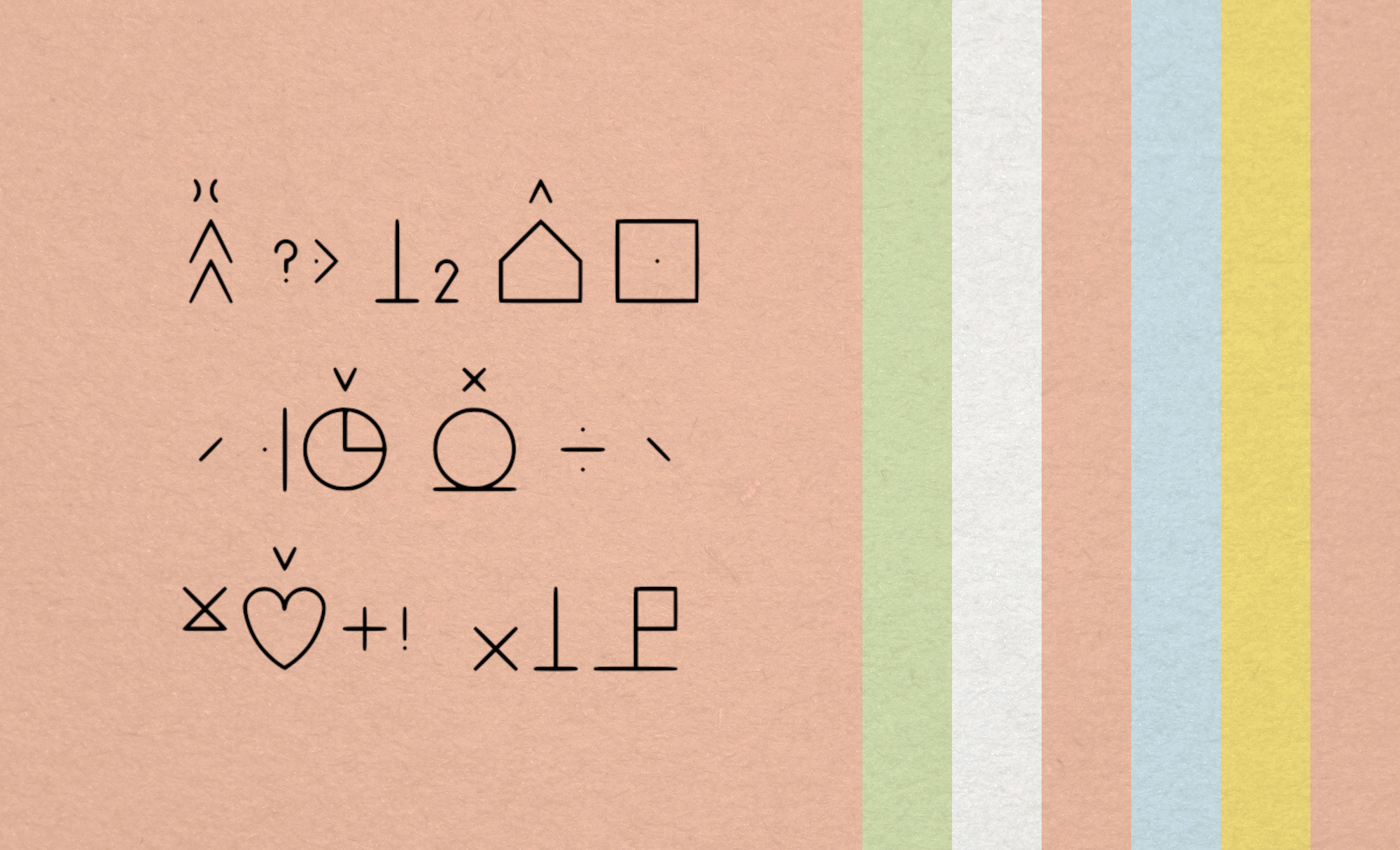
This is most likely less of a blog post and more of an aide-mémoire about the process it takes to migrate the BCI authorised vocabulary to an icon font for easier use in code. This all started when I wanted to build a clone of Whats App that supported Bliss Symbols, Bliss-Chat if you will. I thought this should be a fairly straight forward project. I quickly ran into the brick wall that bliss symbols didn't have a keyboard, so that's OK I just needed to make a small side project and I started making Bliss-Keyboard. But then I ran into how am I going to manage the almost 6000 characters, diacritics and words? Crap So I needed to build a Bliss-Font and a Bliss-React to integrate that font with a React project. So my weekend project is now a 4 month odyssey. Hopefully it helps someone out once it's all said and done.
So Blissymbolics Communication International BCI is the charitable organisation that looks after and maintains the bliss lexicon periodically publishing an authorised vocabulary of characters, diacritics and words. These come in a handful of formats including .svg formats. I should be able to download the files and convert them into an icon font for ease of use. Like all of my other thinking, that too proved to be difficult. Below is a series of steps I used to work through and organise the files so when the next update to the authorised vocabulary is made, this isn't such a rough process.
Download the SVG files labelled with their AV# (authorised vocabulary ID). This is to avoid the reliance on English based limitations of finding symbols. These files are then split up into four key categories (and I'm cool if these categories need reduced or increased - let's call this a starting point). They are Characters (all single character symbols), Diacritics (all supportive marks such as punctuation, indicators, numbers and letters), Words (all multi character words defined) and finally there are a series of Deprecated symbols (indicated in the documentation as _(OLD)).
I can use the documentation to divvy up the symbols based on my categories into groups of id numbers which I can then write to a file and then move around with rsync as below:
rsync -av --remove-source-files --files-from filelist.txt sourceDir/ targetDir/
Now for the tricky bit the .svg fonts that are produced by BCI rely on stroke. While this is a common and very useful feature of .svgs it is completely ignored in the process to generate icon fonts from svgs leaving me with an headache as to why I was generating icons that were invisible. These characters built from strokes need to be converted to use Path and Fill. This can be fairly easily accomplished with the npm package outline-stroke.
Now we can run the npm package fantasticon. Frustration aside this was a beautiful package once you figured out how to use it from the near non-existent documentation. It's a curse in the software world to make the coolest stuff and then nobody ever makes a manual. After the creation process it is a fairly simple case of organising everything into folders and linking the relevant licenses.
While the sentiment above still applies, Fantasticon was throwing some weird issues will filling in areas that were not filled in. So I moved across to using Icomoon to create the font files.
I didn't stop there though. all of the fonts are called using CSS classes in the same way font-awesome is used. But as the files are all named after their AW# it isn't very descriptive to figure out was bs-12375 is instead of using a more descriptive bs-angel_OLD. So I created a conversion chart which then mapped to a JavaScript lookup object the allowed me to open each CSS file in turn go through each line, find the AV# do a lookup and have the English name of the character. That way I could write that back into the CSS file as an alternative class name to be used. Perhaps in future it would make sense to create class names for each of the translated languages available for each symbol.
So this process was a pain, but I took the spreadsheet split out into the four groups. And then I created an extra column for each column and put it's name between :'s, for example for column "AV#" I created a new column in front of the column and added ":av:" to each row. I did this across the form. I took that spreadsheet and exported it as a CSV and opened in an editor and through a series of find/replaces I cleaned up the file into a lookup object.
The steps below are in order and everything used is between pipes, don't forget to notice where spaces are used:
Once this task is done you'll have the mapping functions that will work to translate between the symbol ids and the other languages and (when I get there) work to run the translation and lookup required in the keyboard and resulting phrases.
That's the end. Hopefully this doesn't come up as a task very often. But if it does, here's a map to make it actually take an afternoon.